Spring Boot JPA
JPA(Java Persistence API)是一套 Java 持久化规范,用于将应用程序中的对象映射到关系型数据库。
应用程序的数据访问层通常为域对象提供创建、读取、更新和删除(CRUD)操作,Spring Data JPA 提供了这方面的通用接口以及持久化存储特定的实现,它选择目前最流行之一的 Hibernate 作为 JPA 实现的提供者,旨在简化数据访问层。作为应用程序的开发人员,你只需要编写数据库的存取接口,由 Spring 运行时自动生成这些接口的适当实现,开发人员不需要编写任何具体的实现代码。在 Spring Boot 中,通过使用spring-boot-starter-data-jpa启动器,就能快速开启和使用 Spring Data JPA。
# pom.xml
|
|
1. 编程接口
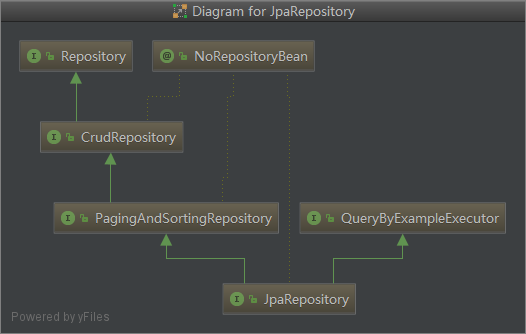
1.1 Repository
这是 Spring Data Jpa 抽象的中心接口,它是一个标记接口。扩展此接口需要传递实体类型和实体的ID字段类型参数,你必须在接口里面声明你自己需要的方法,这些方法由 Spring 在运行时提供具体的实现。
|
|
1.2 CrudRepository
继承自 Repository 接口,它提供了一套 CRUD 操作的方法。扩展此接口需要传递实体类型和实体的ID字段类型参数,你可以不需要再定义基础的 CRUD 操作方法而直接可以使用它们。但在某些场景中你可能不希望接口对外暴露一套完整的增删查改的方法,比如你只希望提供查改的方法而不希望暴露增删的功能。基于这种情况,你可以使用 Repository 接口,并将需要的方法从 CrudRepository 拷贝到其中以选择性的公开 CRUD 方法。
|
|
1.2.1 save
当你需要修改数据库的数据时,你可以调用此方法。当此方法被调用时,它首先判断参数的实体对象是否是新的。如果是新的,则调用 persist 将对象数据 insert 到数据库。如果不是新的,则调用 merge 将对象数据 update/insert 到数据库。源码:spring-data-jpa.jar!\org\springframework\data\jpa\repository\support\SimpleJpaRepository.java
# SimpleJpaRepository 源码片段
|
|
判断实体对象是否是新的,其依据是主键字段是否设置了有效的值。源码:spring-data-commons.jar!\org\springframework\data\repository\core\support\AbstractEntityInformation.java
# AbstractEntityInformation 源码片段
|
|
因此,CrudRepository.save()既有保存又有更新数据的能力。保存一条数据:
|
|
更新数据时,应该先从数据库将记录查询出来,对数据修改完成之后再调用save更新回数据库:
|
|
切勿脑洞大开异想通过设置主键字段的值来直接更新数据库的记录,以下做法是不可取的:
|
|
方法执行完之后悲剧就发生了,除了主键和年龄之外,其余字段的值全部被清空了。观众朋友切勿模仿。
1.2.2 delete
根据主键删除时,主键字段不能为空,并且在数据库中必须得有与主键对应的行记录(通过SELECT查询判断),然后将查询出的行记录删除。
|
|
根据实体删除时,实体对象不能为空,依据实体的主键标识判断数据库中是否有与之对应的行记录,如果有,则将此行删除;如果没有,则调用merge产生 INSERT 语句,然后再删除。
|
|
1.3 PagingAndSortingRepository
继承自 CrudRepository 接口,它提供了一个分页和排序的操作方法。扩展此接口需要传递实体类型和实体的ID字段类型参数,但是通常我们会比较少选择扩展该接口,而更多的是在接口里声明含有 Pageable 或 Sort 类型参数的方法来完成分页或排序的功能。
|
|
1.3.1 排序查询
|
|
或
|
|
1.3.2 分页查询
|
|
1.3.3 分页并排序
|
|
1.4 JpaRepository
继承自 PagingAndSortingRepository 接口,它提供了一组实用的操作方法,如批量操作等。扩展此接口需要传递实体类型和实体的ID字段类型参数,该接口的一部分方法返回 List 类型的实体,与之不同的是,CrudRepository 返回的是 Iterable 类型的实体。
|
|
2. 定义查询方法
Spring Data JPA 在运行时会为接口创建代理对象并为接口声明的方法提供具体的实现。代理提供了两种方式来从方法名中提取查询,一种是从方法名中直接提取查询,另外一种是从方法中提取手工定义的查询语句。代理如何创建查询是由具体的策略来决定的。
| 策略 | 简述 |
|---|---|
| CREATE | 根据方法名构造出一个特定的查询。 具体的做法是从方法名中移除一组已知的前缀,然后解析剩余的部分。 |
| USE_DECLARED_QUERY | 使用查询注解定义的查询语句。如: @Query、@NamedQuery、@NamedNativeQuery |
| CREATE_IF_NOT_FOUND | 默认使用的策略。 它组合了 CREATE 和 USE_DECLARED_QUERY 两个策略。它首先使用 USE_DECLARED_QUERY 策略查找,如果找不到再使用 CREATE 策略。 |
2.1 创建查询
JPA 提供了一种可以根据方法名称直接构造出查询语句的方式,这种方式称为创建查询。在存储库接口中定义的方法,其名称只需按照约定命名,需满足以下的规则:
- 方法名必须以:
findByfind...ByreadByread...ByqueryByquery...BycountBycount...BygetByget...By前缀之一开始命名; - 在第一个
By之后可以添加查询方法的检索条件,可以使用实体的属性名和支持的关键字来组合; - 在第一个
By之前可以添加First或Top关键字,表示返回查询结果的第一条数据。除此之外,关键字First或Top的后面也可以携带数字表示返回前多少条的数据,如Top10; - 在第一个
By之前可以添加Distinct关键字,去掉查询结果中重复的数据; - 查询方法如果设定了X个检索条件,那么,查询方法的参数个数也必须是X个,并且参数必须按与检索条件相同的顺序给出;
- 查询方法同时还可以使用特殊的
Pageable或Sort参数,用于分页或排序,该参数不算在X之内;
2.1.1 查询方法支持的关键字表
| 关键字 | 示例 | JPQL 片段 |
|---|---|---|
| And | findByLastnameAndFirstname | … where x.lastname = ?1 and x.firstname = ?2 |
| Or | findByLastnameOrFirstname | … where x.lastname = ?1 or x.firstname = ?2 |
| Is Equals |
findByFirstname findByFirstnameIs findByFirstnameEquals |
… where x.firstname = ?1 |
| Between | findByStartDateBetween | … where x.startDate between ?1 and ?2 |
| LessThan | findByAgeLessThan | … where x.age < ?1 |
| LessThanEqual | findByAgeLessThanEqual | … where x.age <= ?1 |
| GreaterThan | findByAgeGreaterThan | … where x.age > ?1 |
| GreaterThanEqual | findByAgeGreaterThanEqual | … where x.age >= ?1 |
| After | findByStartDateAfter | … where x.startDate > ?1 |
| Before | findByStartDateBefore | … where x.startDate < ?1 |
| IsNull | findByAgeIsNull | … where x.age is null |
| IsNotNull NotNull |
findByAgeNotNull findByAgeIsNotNull |
… where x.age not null |
| Like | findByFirstnameLike | … where x.firstname like ?1 |
| NotLike | findByFirstnameNotLike | … where x.firstname not like ?1 |
| StartingWith | findByFirstnameStartingWith | … where x.firstname like ?1 (parameter bound with appended %) |
| EndingWith | findByFirstnameEndingWith | … where x.firstname like ?1 (parameter bound with prepended %) |
| Containing | findByFirstnameContaining | … where x.firstname like ?1 (parameter bound wrapped in %) |
| OrderBy | findByAgeOrderByLastnameDesc | … where x.age = ?1 order by x.lastname desc |
| Not | findByLastnameNot | … where x.lastname <> ?1 |
| In | findByAgeIn(Collection<Age> ages) | … where x.age in ?1 |
| NotIn | findByAgeNotIn(Collection<Age> age) | … where x.age not in ?1 |
| True | findByActiveTrue() | … where x.active = true |
| False | findByActiveFalse() | … where x.active = false |
| IgnoreCase | findByFirstnameIgnoreCase | … where UPPER(x.firstame) = UPPER(?1) |
2.1.2 查询方法支持的返回值表
| 类型 | 简述 |
|---|---|
| void | 不需要返回值 |
| Primitives | Java 基本数据类型 |
| Wrapper | Java 基本数据类型对应的包装类型 |
| T | 期望返回的实体类型,查询方法至多只能返回一条数据结果,多于一条数据的结果将抛出异常,没有查询到数据结果,则返回 null |
| Iterator<T> | 迭代器类型 |
| Collection<T> | 集合类型 |
| List<T> | List 集合类型 |
| Optional<T> | Java8 Optional 类型 |
| Stream<T> | Java8 Stream 类型 |
| Future<T> | Java8 Future 类型,使用@Async注解标注查询方法,并且需要启用 Spring 异步方法执行的功能 |
| CompletableFuture<T> | Java8 CompletableFuture 类型,使用@Async注解标注查询方法,并且需要启用 Spring 异步方法执行的功能 |
| ListenableFuture | Spring ListenableFuture 类型,使用@Async注解标注查询方法,并且需要启用 Spring 异步方法执行的功能 |
| Slice | 分页相关 |
| Page<T> | 分页相关 |
在存储库接口中定义的方法,只需要按照约定命名,就能快速实现查询的功能:
|
|
创建查询的优点是,不用编写查询语句,处理检索条件简单的查询非常方便,而且方法的可读性很高。但是对于检索条件过多的查询方法,很容易导致方法名称过长,可读性降低。
2.2 命名查询
JPA 提供了一种可以将查询语句从存储库接口中独立出来的方式,这种方式称为命名查询。它允许我们通过使用@NamedQuery或@NamedNativeQuery注解将预定义好的静态查询语句直接绑定到目标方法。
命名查询的优点是,查询语句集中,便于维护,查询方法的名称不受约束,编写复杂的查询只要合理命名也不会导致产生过长的方法名称。但是由于命名查询的注解都是标注在实体类中,因此它不适合用于大量定义查询语句,这样会使得实体类变得过于臃肿。
2.2.1 @NamedQuery
| 参数 | 简述 |
|---|---|
| name | 用于定义查询的方法名称,该方法名称是全局范围的,为避免不同的实体定义了相同的方法名称而导致的查询冲突,JPA 明确规定自定义的方法名称的命名需要满足约定: 实体类的简单类名 + “.” + 自定义的查询方法名称 |
| query | 用于定义 JPQL 查询语句(附:查询参数语法) |
使用@NamedQuery注解需要在实体类中标注使用:
|
|
然后在存储库接口中声明与这些名称相同的方法即可:
|
|
2.2.2 @NamedNativeQuery
注解@NamedNativeQuery与@NamedQuery的用法和作用相类似。不同的是,@NamedQuery使用的是 JPQL 查询语言,可以做到跨数据库平台。而@NamedNativeQuery使用的是 SQL 查询语言,与特定的数据库平台紧密相关。@NamedNativeQuery注解也是需要在实体类中标注使用:
|
|
相比较@NamedQuery注解而言,多了一个resultClass参数,它用于定义查询结果的返回值类型。
|
|
2.3 @Query 查询
使用@Query注解可以直接将查询语句绑定到存储库接口的方法上,它同时支持 JPQL 和 SQL 查询语言。另外,它对方法名称的命名没有约束,并且查询语句就编写在方法的上方,方便追踪查询方法的具体作用。
2.3.1 JPQL 查询
注解@Query默认使用的就是 JPQL 查询语言:
|
|
2.3.2 SQL 查询
在@Query注解中,如果要使用 SQL 查询语言,nativeQuery参数需要标记为 true:
|
|
2.3.3 LIKE 查询
在@Query注解中,可以使用高级的LIKE表达式查询(命名查询不支持):
|
|
2.3.4 分页查询
如果你使用的是@Query的 JPQL 查询语言,只需在查询方法中添加Pageable参数就能实现分页查询:
|
|
如果你使用的不是 JPQL 而是 SQL 查询语言,则还需提供countQuery参数用于查询结果的总条数:
|
|
Spring Data JPA 官方文档给出了@Query注解使用本地查询分页的基础示例(Example 51),但是按照该示例编写出的代码运行时报错。
2.3.5 排序查询
如果你使用的是@Query的 JPQL 查询语言,只需在查询方法中添加Sort参数就能实现排序功能:
|
|
注:@Query的本地查询(SQL 查询)不支持这种动态排序的功能。
如果是分页查询需要排序支持,可以通过向PageRequest构造器传入Sort对象来完成:
|
|
2.3.6 SpEL 表达式
Spring Data JPA 1.4 版本开始引入 SpEL 表达式,目前支持的 SpEL 表达式非常有限(目前仅有一个):
| 变量 | 描述 |
|---|---|
| entityName | 存储库接口关联的实体类的实体名称。如果实体类@Entity注解设置了name属性,那么将使用它。否则将使用实体类的简单类名。 |
|
|
2.3.7 更新查询
@Query注解除了可以用来定义查询语句还可以用来定义更新语句(UPDATE/DELETE),在@Query标注的方法上只需要使用@Modifying注解就能实现更新的行为:
|
|
示例项目开发环境:Java-8、Maven-3、IntelliJ IDEA-2017、Spring Boot-1.5.2.RELEASE
完整示例项目链接:spring-boot-jpa-sample
参考文档文献链接:http://docs.spring.io/spring-data/jpa/docs/1.11.1.RELEASE/reference/html