1. cd 命令 change directory(更改目录)。
用于切换工作目录。是最基本的 Linux 操作系统命令。
1) 使用cd不带任何参数,可进入当前用户的主目录:
1
2
[fanlychie@129host apache-tomcat-8.0.45]$ cd
[fanlychie@129host ~]$
2) 使用cd ~也可进入当前用户的主目录:
1
2
[fanlychie@129host apache-tomcat-8.0.45]$ cd ~
[fanlychie@129host ~]$
3) 使用cd ..返回上级目录(..用于表示上级目录,如返回上两级目录则应为cd ../..):
1
2
[fanlychie@129host webapps]$ cd ..
[fanlychie@129host apache-tomcat-8.0.45]$
4) 使用cd -返回进入当前目录之前所在的目录:
1
2
3
[fanlychie@129host apache-tomcat-8.0.45]$ cd -
/home/fanlychie/apache-tomcat-8.0.45/webapps
[fanlychie@129host webapps]$
2. pwd 命令 print work directory(打印工作目录)。
用于查看当前工作目录的路径,通常不需要带参数。
1
2
$ pwd
/home/fanlychie/apache-tomcat-8.0.45
3. mkdir 命令 make directory(创建目录)。
用于创建文件系统的目录(文件夹)。
1) 创建一个名称为“dirname”的目录:
2)使用-p, --parents选项,当创建的目录的父目录不存在时,父目录也会一起被创建:
1
$ mkdir -p pathname/dirname
该命令用于创建“dirname”目录,如果其父目录“pathname”尚未存在,则“pathname”目录会被一起创建。
3) 使用{..}可以批量创建目录,如创建2018-01-01…2018-01-15…2018-01-31共31个目录:
1
$ mkdir 2018-01-{01..31}
4) 使用{,}可以批量创建目录,如创建2018-01-01、2018-01-15、2018-01-31共3个目录:
1
$ mkdir 2018-01-{01,15,31}
4. ls 命令 list(列表信息)。
用于显示目录内容的列表信息。
1) 使用ls命令查看当前工作目录的列表信息:
1
2
$ ls
Catalina catalina.policy catalina.properties context.xml logging.properties server.xml tomcat-users.xml tomcat-users.xsd web.xml
2) 使用ll命令查看当前工作目录的列表信息:
1
2
3
4
5
6
7
8
9
10
11
$ ll
total 220
drwxr-xr-x. 3 fanlychie fanlychie 4096 2017-11-11 17:05:03 Catalina
-rw-------. 1 fanlychie fanlychie 13688 2017-06-26 20:09:48 catalina.policy
-rw-------. 1 fanlychie fanlychie 7299 2017-06-26 20:09:48 catalina.properties
-rw-------. 1 fanlychie fanlychie 1577 2017-06-26 20:09:48 context.xml
-rw-------. 1 fanlychie fanlychie 3387 2017-06-26 20:09:48 logging.properties
-rw-------. 1 fanlychie fanlychie 6458 2017-11-11 17:24:47 server.xml
-rw-------. 1 fanlychie fanlychie 2155 2017-11-11 18:23:43 tomcat-users.xml
-rw-------. 1 fanlychie fanlychie 2634 2017-06-26 20:09:48 tomcat-users.xsd
-rw-------. 1 fanlychie fanlychie 168496 2017-06-26 20:09:48 web.xml
ll是ls -l命令的别名(-l选项是用长格式方式显示信息,其每一个内容项都占据一行)
序号 示例 描述 第一列 drwxr-xr-x 文件或目录的权限位描述符 第二列 3 如果是一个文件,则表示文件的个数(数值必然是1) 第三列 fanlychie 文件或目录的属主(即所有者) 第四列 fanlychie 文件或目录的属组 第五列 4096 文件的大小,单位是B 第六列 2017-11-11 文件或目录最后变更的日期 第七列 17:05:03 文件或目录最后变更的时间 第八列 Catalina 文件或目录的名称
其中,第一列drwxr-xr-x的第一位表示文件系统对象类型,剩下的九位以每三位为一组表示:
常见的 Linux 文件系统对象类型有:
类型 描述 - 普通文件 d 目录(文件夹) l 符号连接(包括软链接和硬链接),它实质指向另一个文件
3) 使用-a, --all选项,会把以.和..开头的隐藏文件或目录信息也罗列显示出来:
1
2
3
4
5
6
7
8
9
10
11
12
13
$ ll -a
total 228
drwxr-xr-x. 3 fanlychie fanlychie 4096 2018-04-25 07:18:36 .
drwxrwxr-x. 9 fanlychie fanlychie 4096 2017-11-11 17:04:10 ..
drwxrwxr-x. 3 fanlychie fanlychie 4096 2017-11-11 17:05:03 Catalina
-rw-------. 1 fanlychie fanlychie 13688 2017-06-26 20:09:48 catalina.policy
-rw-------. 1 fanlychie fanlychie 7299 2017-06-26 20:09:48 catalina.properties
-rw-------. 1 fanlychie fanlychie 1577 2017-06-26 20:09:48 context.xml
-rw-------. 1 fanlychie fanlychie 3387 2017-06-26 20:09:48 logging.properties
-rw-------. 1 fanlychie fanlychie 6458 2017-11-11 17:24:47 server.xml
-rw-------. 1 fanlychie fanlychie 2155 2017-11-11 18:23:43 tomcat-users.xml
-rw-------. 1 fanlychie fanlychie 2634 2017-06-26 20:09:48 tomcat-users.xsd
-rw-------. 1 fanlychie fanlychie 168496 2017-06-26 20:09:48 web.xml
4) 罗列指定路径(文件或目录路径)下的内容信息,如查看“Catalina”目录下的内容信息:
1
2
3
$ ll Catalina
total 4
drwxrwxr-x. 2 fanlychie fanlychie 4096 2018-04-24 11:21:47 localhost
5) 使用-t选项,可以按文件或目录的修改时间排序(最新的排在最前面, 即降序):
1
2
3
4
5
6
7
8
9
10
11
$ ll -t
total 220
-rw-------. 1 fanlychie fanlychie 2155 2017-11-11 18:23:43 tomcat-users.xml
-rw-------. 1 fanlychie fanlychie 6458 2017-11-11 17:24:47 server.xml
drwxrwxr-x. 3 fanlychie fanlychie 4096 2017-11-11 17:05:03 Catalina
-rw-------. 1 fanlychie fanlychie 13688 2017-06-26 20:09:48 catalina.policy
-rw-------. 1 fanlychie fanlychie 7299 2017-06-26 20:09:48 catalina.properties
-rw-------. 1 fanlychie fanlychie 1577 2017-06-26 20:09:48 context.xml
-rw-------. 1 fanlychie fanlychie 3387 2017-06-26 20:09:48 logging.properties
-rw-------. 1 fanlychie fanlychie 2634 2017-06-26 20:09:48 tomcat-users.xsd
-rw-------. 1 fanlychie fanlychie 168496 2017-06-26 20:09:48 web.xml
6) 使用-r, --reverse选项,可以反向排序,默认是按文件或目录名称:
1
2
3
4
5
6
7
8
9
10
11
$ ll -r
total 220
-rw-------. 1 fanlychie fanlychie 168496 2017-06-26 20:09:48 web.xml
-rw-------. 1 fanlychie fanlychie 2634 2017-06-26 20:09:48 tomcat-users.xsd
-rw-------. 1 fanlychie fanlychie 2155 2017-11-11 18:23:43 tomcat-users.xml
-rw-------. 1 fanlychie fanlychie 6458 2017-11-11 17:24:47 server.xml
-rw-------. 1 fanlychie fanlychie 3387 2017-06-26 20:09:48 logging.properties
-rw-------. 1 fanlychie fanlychie 1577 2017-06-26 20:09:48 context.xml
-rw-------. 1 fanlychie fanlychie 7299 2017-06-26 20:09:48 catalina.properties
-rw-------. 1 fanlychie fanlychie 13688 2017-06-26 20:09:48 catalina.policy
drwxrwxr-x. 3 fanlychie fanlychie 4096 2017-11-11 17:05:03 Catalina
7) 组合-r选项,按文件或目录的修改时间升序排序:
1
2
3
4
5
6
7
8
9
10
11
$ ll -rt
total 220
-rw-------. 1 fanlychie fanlychie 168496 2017-06-26 20:09:48 web.xml
-rw-------. 1 fanlychie fanlychie 2634 2017-06-26 20:09:48 tomcat-users.xsd
-rw-------. 1 fanlychie fanlychie 3387 2017-06-26 20:09:48 logging.properties
-rw-------. 1 fanlychie fanlychie 1577 2017-06-26 20:09:48 context.xml
-rw-------. 1 fanlychie fanlychie 7299 2017-06-26 20:09:48 catalina.properties
-rw-------. 1 fanlychie fanlychie 13688 2017-06-26 20:09:48 catalina.policy
drwxrwxr-x. 3 fanlychie fanlychie 4096 2017-11-11 17:05:03 Catalina
-rw-------. 1 fanlychie fanlychie 6458 2017-11-11 17:24:47 server.xml
-rw-------. 1 fanlychie fanlychie 2155 2017-11-11 18:23:43 tomcat-users.xml
8) 使用-S选项,可以按文件或目录的大小排序(最大的排在最前面,即降序):
1
2
3
4
5
6
7
8
9
10
11
$ ll -S
total 220
-rw-------. 1 fanlychie fanlychie 168496 2017-06-26 20:09:48 web.xml
-rw-------. 1 fanlychie fanlychie 13688 2017-06-26 20:09:48 catalina.policy
-rw-------. 1 fanlychie fanlychie 7299 2017-06-26 20:09:48 catalina.properties
-rw-------. 1 fanlychie fanlychie 6458 2017-11-11 17:24:47 server.xml
drwxrwxr-x. 3 fanlychie fanlychie 4096 2017-11-11 17:05:03 Catalina
-rw-------. 1 fanlychie fanlychie 3387 2017-06-26 20:09:48 logging.properties
-rw-------. 1 fanlychie fanlychie 2634 2017-06-26 20:09:48 tomcat-users.xsd
-rw-------. 1 fanlychie fanlychie 2155 2017-11-11 18:23:43 tomcat-users.xml
-rw-------. 1 fanlychie fanlychie 1577 2017-06-26 20:09:48 context.xml
9) 使用-h, --human-readable选项,以易读方式来显示文件或目录的大小(默认大小是以B作为单位,-h, --human-readable选项会自动的将其转换为K或M或G单位来显示):
1
2
3
4
5
6
7
8
9
10
11
$ ll -h
total 220K
drwxrwxr-x. 3 fanlychie fanlychie 4.0K 2017-11-11 17:05:03 Catalina
-rw-------. 1 fanlychie fanlychie 14K 2017-06-26 20:09:48 catalina.policy
-rw-------. 1 fanlychie fanlychie 7.2K 2017-06-26 20:09:48 catalina.properties
-rw-------. 1 fanlychie fanlychie 1.6K 2017-06-26 20:09:48 context.xml
-rw-------. 1 fanlychie fanlychie 3.4K 2017-06-26 20:09:48 logging.properties
-rw-------. 1 fanlychie fanlychie 6.4K 2017-11-11 17:24:47 server.xml
-rw-------. 1 fanlychie fanlychie 2.2K 2017-11-11 18:23:43 tomcat-users.xml
-rw-------. 1 fanlychie fanlychie 2.6K 2017-06-26 20:09:48 tomcat-users.xsd
-rw-------. 1 fanlychie fanlychie 165K 2017-06-26 20:09:48 web.xml
10) 使用-R, --recursive选项,可以递归显示路径下的子目录下的树信息:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
$ ll -R
.:
total 220
drwxrwxr-x. 3 fanlychie fanlychie 4096 2017-11-11 17:05:03 Catalina
-rw-------. 1 fanlychie fanlychie 13688 2017-06-26 20:09:48 catalina.policy
-rw-------. 1 fanlychie fanlychie 7299 2017-06-26 20:09:48 catalina.properties
-rw-------. 1 fanlychie fanlychie 1577 2017-06-26 20:09:48 context.xml
-rw-------. 1 fanlychie fanlychie 3387 2017-06-26 20:09:48 logging.properties
-rw-------. 1 fanlychie fanlychie 6458 2017-11-11 17:24:47 server.xml
-rw-------. 1 fanlychie fanlychie 2155 2017-11-11 18:23:43 tomcat-users.xml
-rw-------. 1 fanlychie fanlychie 2634 2017-06-26 20:09:48 tomcat-users.xsd
-rw-------. 1 fanlychie fanlychie 168496 2017-06-26 20:09:48 web.xml
./Catalina:
total 4
drwxrwxr-x. 2 fanlychie fanlychie 4096 2018-04-24 11:21:47 localhost
./Catalina/localhost:
total 4
-rw-------. 1 fanlychie fanlychie 426 2018-04-24 11:21:47 context.xml
5. rm 命令 remove(移除)。
用于删除文件或目录。
1) 使用-f, --force选项,强行执行删除操作,即使删除的文件不存在也不会出现警告。
1
$ rm -f catalina.2017-11-12.log
2) 使用-r, -R, --recursive选项,可以删除一个目录(该目录下的所有文件和子目录都会被删除):
3) 使用-v, --verbose选项,可以回显执行过程:
1
2
$ rm -v catalina.2017-11-11.log
removed `catalina.2017-11-11.log`
6. mv 命令 move(移动)。
用于移动文件或目录到另外一个目录中,也可用于重命名文件或目录。
1) 将源文件“zoo_sample.cfg”的名称重命名为“zoo.cfg”:
1
$ mv zoo_sample.cfg zoo.cfg
2) 将源目录“config”的名称重命名为“conf”:
3) 将“zoo_sample.cfg”文件移动到子目录“conf”中:
1
$ mv zoo_sample.cfg conf/
若“conf”中已存在一个名为“zoo_sample.cfg”的文件,则新的文件会直接覆盖老的文件。
4) 将文件“zoo_sample.cfg”移动到子目录“conf”中,并将文件重命名为“zoo.cfg”:
1
$ mv zoo_sample.cfg conf/zoo.cfg
5) 将目录“node1”中的子目录“conf/”移动到目录“node2/”中:
如果“node2”目录中已经存在一个名称为“conf”的子目录并且该子目录的内容不为空,则会报出警告,不能成功的进行移动。除非先把“node2”目录中的“conf”子目录删除或者使用-b选项(如果移动的文件或目录在目标目录中已经存在,则移动前会自动进行备份,备份的文件或目录默认是以原名称+~结束)进行移动:mv -b node1/conf/ node2/。
7. chmod 命令 change mode(改变模式)。
用于变更文件或目录的权限。
Linux 系统的文件或目录是由读取(r)、写入(w)、执行(x)三种权限共同来决定。执行ll(ls -l)命令展示出来的第一列就是文件或目录的权限信息(参考「ls 命令」 )。
属主 (u) :文件或目录的创建者,或被指定的文件或目录的所有者;
属组 (g) :文件或目录的所属用户组;
其它人 (o) :既不是属主又不是属组里面的其它用户;
文件或目录的读取(r)、写入(w)、执行(x)权限控制:
字符
数值
描述
r
4
读取权限(如果是目录,那就是查看目录里面内容的权限)
w
2
写入权限
x
1
执行权限(如果是目录,那就是切换(cd)到目录的权限)
-
0
没有权限
假设现有一文件“my.sh”,其初始权限如下:
1
-rw-r--r--. 1 fanlychie fanlychie 601 2018-04-25 09:43:38 my.sh
1) 给文件或目录赋权,属主u=r|w|x,属组g=r|w|x,其他人o=r|w|x,所有a=r|w|x:
1
2
3
4
$ chmod u=rwx my.sh
$ ll
total 4
-rwxr--r--. 1 fanlychie fanlychie 601 2018-04-25 09:43:38 my.sh
如果想要同时为多个所属组赋权,使用英文逗号分隔:
1
2
3
4
$ chmod g=rx,o=rx my.sh
$ ll
total 4
-rwxr-xr-x. 1 fanlychie fanlychie 601 2018-04-25 09:43:38 my.sh
2) 变更文件或目录的权限,属主u±r|w|x,属组g±r|w|x,其他人o±r|w|x,所有a±r|w|x(其中+为增加相应的权限,-为删除相应的权限):
1
2
3
4
$ chmod o-x my.sh
$ ll
total 4
-rwxr-xr--. 1 fanlychie fanlychie 601 2018-04-25 09:43:38 my.sh
如果想要同时变更多个所属组权限,使用英文逗号分隔:
1
2
3
4
$ chmod u-x,g-x my.sh
$ ll
total 4
-rw-r--r--. 1 fanlychie fanlychie 601 2018-04-25 09:43:38 my.sh
3) 使用数值代码变更文件或目录的权限,如将“my.sh”的文件权限修改为“755”(“rwxr-xr-x”):
1
2
3
4
$ chmod 755 my.sh
$ ll
total 4
-rwxr-xr-x. 1 fanlychie fanlychie 601 2018-04-25 09:43:38 my.sh
4) 使用-R, --recursive选项,可以修改一个目录以及该目录下所有的文件的权限:
1
2
3
4
5
6
7
8
9
$ chmod -R 750 conf/
$ ll -R
.:
total 4
drwxr-x---. 2 fanlychie fanlychie 4096 2018-04-25 10:10:23 conf
./conf:
total 4
-rwxr-x---. 1 fanlychie fanlychie 601 2018-04-25 09:43:38 my.sh
8. chown 命令 change owner(改变所有者)。
用于变更文件或目录的属主和属组。只有文件或目录的创建者或管理员用户才有权限操作。
ll(ls -l)命令展示出的第三和第四列分别就是文件或目录的属主和属组信息(参考「ls 命令」 )。
1
drwxr-xr-x. 3 root root 4096 2018-04-25 09:58:44 test
1) 变更文件或目录的属主和属组,chown 属主:属组 文件或目录:
1
2
3
4
5
6
7
8
9
10
11
12
13
.:
total 4
drwxr-xr-x. 3 fanlychie fanlychie 4096 2018-04-25 09:58:44 test
./test :
total 4
drwxr-x---. 2 root root 4096 2018-04-25 10:10:23 conf
./test /conf:
total 4
-rwxr-x---. 1 root root 601 2018-04-25 09:43:38 my.cfg
使用-R, --recursive选项,可以变更目录以及该目录下所有内容的属主和属组:
1
2
3
4
5
6
7
8
9
10
11
12
13
.:
total 4
drwxr-xr-x. 3 fanlychie fanlychie 4096 2018-04-25 09:58:44 test
./test :
total 4
drwxr-x---. 2 fanlychie fanlychie 4096 2018-04-26 05:30:17 conf
./test /conf:
total 4
-rwxr-x---. 1 fanlychie fanlychie 601 2018-04-25 09:43:38 my.cfg
9. cp 命令 copy(复制)。
用于复制文件或目录。
1) 将“index.html”文件复制到“WEB-INF”目录中:
1
$ cp index.html WEB-INF/
2) 将“index.html”文件复制到“WEB-INF”目录中,并重命名为“index.htm”:
1
$ cp index.html WEB-INF/index.htm
3) 使用-R, -r, --recursive选项,可以将一个目录中的所有内容复制到另外一个目录中。 如将“jsp”目录(包括该目录以及该目录下的所有内容)复制到“WEB-INF”目录中:
4) 如果复制的源文件或目录在目标目录中已经存在,则默认会覆盖目标目录中的文件或目录。 使用-b选项可以备份目标目录中的文件或目录。备份的文件或目录的默认后缀名是是带~结尾。
1
2
3
4
5
6
7
8
9
10
11
$ cp -b index.html WEB-INF/
$ ll WEB-INF/
total 44
drwxr-xr-x. 20 fanlychie fanlychie 4096 2017-11-11 17:04:10 classes
-rw-r--r--. 1 fanlychie fanlychie 1126 2018-04-26 06:06:21 index.html
-rw-r--r--. 1 fanlychie fanlychie 1126 2018-04-26 06:04:57 index.html~
drwxr-xr-x. 22 fanlychie fanlychie 4096 2018-04-26 06:03:07 jsp
drwxr-xr-x. 2 fanlychie fanlychie 4096 2017-11-11 17:04:10 jsp2
drwxr-xr-x. 2 fanlychie fanlychie 4096 2017-11-11 17:04:10 lib
drwxr-xr-x. 2 fanlychie fanlychie 4096 2017-11-11 17:04:10 tags
-rw-r--r--. 1 fanlychie fanlychie 14554 2017-06-26 20:09:51 web.xml
如果没有-b选项,则源文件“index.html”会直接覆盖“WEB-INF”目录中的“index.html”文件;-b选项,源文件“index.html”在覆盖“WEB-INF”目录中的“index.html”文件之前,“WEB-INF”目录中的“index.html”文件会自动做一个备份,备份的文件名称就是为“index.html~”;
10. scp 命令 secure copy(安全复制)。
用于远程文件或目录的安全拷贝。它和cp命令类似,但cp命令只能在本机内对文件或目录进行拷贝。而scp命令能够在两台服务器之间跨服务器拷贝文件或目录。
1) 将“192.168.139.129”服务器中的“index.html”拷贝到“192.168.139.130”服务器中: 语法:scp 本机源文件 远程登录主机的用户名@远程主机IP:复制到远程主机的目标路径
1
$ scp index.html fanlychie@192.168.139.130:/home/fanlychie/test /
如果远程目标机中已经存在该文件,则执行完命令之后,目标机中的文件将会被覆盖掉。
2) 使用-P选项,可以指定远程主机的端口号,默认是22端口,如果不是,可以使用该项来指定。
1
$ scp -P 33 index.html fanlychie@192.168.139.130:/home/fanlychie/test /
3) 使用-r选项,可以将本机的一个目录拷贝到另一台远程主机的目标目录中:
1
$ scp -r jsp/ fanlychie@192.168.139.130:/home/fanlychie/test /
如果远程目标机中已经存在该目录,则执行完命令之后,目标机中的目录将会被覆盖掉。
4) 除此之外,还可以反过来,在本机执行命令,将远程主机中的文件或目录拷贝到本机: 语法:scp 远程登录主机的用户名@远程主机IP:远程主机的源文件 本机目录
1
$ scp fanlychie@192.168.139.130:/home/fanlychie/test /index.html ./index.htm
远程拷贝目录与拷贝文件的方式相似,只需要加-r选项。
5) 将“192.168.139.129”中的“index.html”拷贝到“192.168.139.130”并重命名为“idx.html”:
1
$ scp index.html fanlychie@192.168.139.130:/home/fanlychie/test /idx.html
拷贝目录与拷贝文件的方式相似,只需要加-r选项。
11. cat 命令 concatenate(串联)。
用于将文件内容打印到标准输出设备上。适合用于查看小文件的内容。
1) 使用-n, --number选项,会对文件里面的每一行内容用数字进行编号:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
$ cat -n zoo.cfg
1
2 tickTime=2000
3
4
5
6 initLimit=10
7
8
9
10 syncLimit=5
11
12
13
14
15 dataDir=/home/fanlychie/zookeeper/data
16
17
18 dataLogDir=/home/fanlychie/zookeeper/logs
19
20
21 clientPort=2181
2) 使用-b, --number-nonblank选项,会对文件内容的非空白行用数字进行编号:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
$ cat -b zoo.cfg
1
2 tickTime=2000
3
4
5 initLimit=10
6
7
8 syncLimit=5
9
10
11
12 dataDir=/home/fanlychie/zookeeper/data
13 dataLogDir=/home/fanlychie/zookeeper/logs
14
15 clientPort=2181
3) 使用-s, --squeeze-blank选项,如果连续出现的多个空行就会压缩成一行显示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
$ cat -s zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/home/fanlychie/zookeeper/data
dataLogDir=/home/fanlychie/zookeeper/logs
clientPort=2181
4) 去掉空白行:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
$ cat zoo.cfg | grep -v ^$
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/home/fanlychie/zookeeper/data
dataLogDir=/home/fanlychie/zookeeper/logs
clientPort=2181
其中,|是管道。^$是正则表达式,用于匹配空格。grep的用法可参考xxx。
5) 去掉“#”注释行:
1
2
3
4
5
6
7
8
9
10
11
12
13
$ cat zoo.cfg | grep -v ^
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/home/fanlychie/zookeeper/data
dataLogDir=/home/fanlychie/zookeeper/logs
clientPort=2181
其中,|是管道。^#是正则表达式,用于匹配“#”开头的行。grep的用法可参考xxx。
6) 去掉空白行和注释行:
1
2
3
4
5
6
7
$ cat zoo.cfg | grep -v ^$ | grep -v ^
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/home/fanlychie/zookeeper/data
dataLogDir=/home/fanlychie/zookeeper/logs
clientPort=2181
12. more 命令 用于以分页的形式来展示文本文件的内容。适合用于查看较大文件的内容。
该命令每次显示一屏的内容,在屏幕的左下方会出现--More--(n%)的内容浏览进度条提示。此外,该命令还支持按键操作响应事件,常用的按键操作有:
按键
描述
回车键
前进一行(向下滚动一行)
空格键
前进一屏(向下滚动一屏)
f
前进一屏(向下滚动一屏)
b
后退一屏(向上滚动一屏)
=
显示当前行的行号
q
退出命令
/pattern
搜索字符,匹配的字符不高亮,只能向下(向文件尾)搜索(按“n”键搜索下一个)
1) 使用-s选项,如果文件内容中连续出现的多个空行则会压缩成一行显示:
2) 使用+n选项,可以从指定的第n行开始显示,如从第37行开始显示:
3) 使用-n选项,可以定义每屏显示的行数,如每屏显示10行:
4) 使用+/pattern选项,可以从匹配到的搜索串处开始显示,如从“Exception”出现的地方开始显示:
1
$ more +/Exception catalina.out
13. less 命令 与more命令相似,但功能比more命令更强。
用于以分页的形式来展示文本文件的内容。适合用于查看较大文件的内容。
该命令每次显示一屏的内容,同时它还支持按键操作响应事件,常用的按键操作有:
按键
描述
回车键
前进一行(向下滚动一行)
空格键
前进一屏(向下滚动一屏)
f
前进一屏(向下滚动一屏)
b
后退一屏(向上滚动一屏)
d
前进半屏(向下滚动半屏)
u
后退半屏(向上滚动半屏)
q
退出命令
PgUp(↑)
向上翻一屏
PgDn(↓)
向下翻一屏
/pattern
向下搜索,匹配的字符高亮,按n在同一个方向搜索下一个,按N反方向搜索上一个
?pattern
向上搜索,匹配的字符高亮,按n在同一个方向搜索下一个,按N反方向搜索上一个
1) 使用-s选项,如果文件内容中连续出现的多个空行则会压缩成一行显示:
2) 使用+n选项,可以从指定的第n行开始显示,如从第37行开始显示:
3) 使用-n选项,可以定义每屏显示的行数,如每屏显示10行:
4) 使用+/pattern选项,可以从匹配到的搜索串处开始显示,如从“Exception”出现的地方开始显示:
1
$ less +/Exception catalina.out
5) 使用-N选项,显式文件内容的行号:
6) 使用-m选项,在右下角显示文件浏览进度的百分比数:
14. head 命令 用来查看文件的前几行(默认是前10行)的内容。
1) 查看“catalina.out”文件(查看前10行):
如果想查看指定的前几行,可以使用-n参数,例如查看前20行:
15. tail 命令 用来查看文件末尾的内容(默认是末尾10行)。
1) 查看“catalina.out”文件(查看末尾的10行):
如果想查看指定的末尾几行,可以使用-n参数,例如查看末尾20行:
2) 使用-f, --follow选项,可以跟随读取文件(常用于查看日志文件):
16. tar 命令 tape archive(最初是用来在磁带上创建档案)。
用于将一个文件或目录打包压缩成一个文件,或用于将一个文件或目录从压缩包里解压缩出来。
打包:它仅仅是将一个文件或一个目录下的所有内容汇总成一个总的文件;
压缩:则是指通过某些算法(如gzip、bzip2),将一个文件压缩成一个体积更小的文件;
1) 将“logs”目录打包并压缩成“logs.tar.gz”文件:
1
$ tar zcvf logs.tar.gz logs/
tar命令是汇总成“*.tar”文件。z选项是采用“gzip”算法压缩成“*.gz”文件。
2) 查看“*.tar.gz”压缩包文件里面的内容:
3) 解压缩“*.tar.gz”压缩包文件里面的内容:
17. ping 命令 用于测试两台主机之间网络的连通性。
1) ping 主机 IP“192.168.1.100”的网络连通性:
1
2
3
4
5
$ ping 192.168.1.100
PING 192.168.1.100 (192.168.1.100) 56(84) bytes of data.
64 bytes from 192.168.1.100: icmp_seq=1 ttl=128 time=0.801 ms
64 bytes from 192.168.1.100: icmp_seq=2 ttl=128 time=0.610 ms
64 bytes from 192.168.1.100: icmp_seq=3 ttl=128 time=0.581 ms
按ctrl + c组合键中断。
2) ping 公网域名“baidu.com”的外网连通性(如果能ping通表明主机能正常访问外网,反之则不能):
1
2
3
4
5
$ ping baidu.com
PING baidu.com (220.181.57.216) 56(84) bytes of data.
64 bytes from 220.181.57.216: icmp_seq=1 ttl=128 time=40.9 ms
64 bytes from 220.181.57.216: icmp_seq=2 ttl=128 time=39.5 ms
64 bytes from 220.181.57.216: icmp_seq=3 ttl=128 time=40.2 ms
3) 使用-c选项,可以指定 ping 的次数。如 ping 测试3次:
1
$ ping -c 3 192.168.1.100
17. ssh 命令 用于在一台Linux主机远程登录到另外一台Linux主机。
1) 用“fanlychie”账户登录到远程主机“192.168.139.129”,语法ssh 远程主机用户名@远程主机IP:
1
$ ssh fanlychie@192.168.139.129
如果当前Linux主机是首次远程登录到目标主机,它会询问你“Are you sure you want to continue connecting (yes/no)?”键入“yes”敲回车即可。然后它会要求你输入远程主机用户名登录到主机IP的密码“fanlychie@192.168.139.129’s password:”键入密码敲回车即可。
如果当前Linux主机也是以“fanlychie”账户登录的,则可以去掉登录远程主机的用户名:
它默认是以当前Linux主机登录的用户名登录远程IP主机。
2) 使用p选项,可以指定登录远程主机的端口(默认是22端口),例如指定33端口:
1
$ ssh -p 33 fanlychie@192.168.139.129
18. 管道命令 管道|,它能将上一个命令的正确执行的输出传递给下一个命令,作为下一个命令的标准输入。
1) 查看当前目录下的文件,按大小排序,然后分页查看:
1
2
3
4
5
6
$ ll -Sh | less
总用量 79M
-rw-rw-r-- 1 fanlychie fanlychie 5.5M 2018-05-10 09:07:23 webtest.log.2018-05-10
-rw-rw-r-- 1 fanlychie fanlychie 3.9M 2018-05-09 12:22:33 servicetest.log.2018-05-09
-rw-rw-r-- 1 fanlychie fanlychie 3.5M 2018-05-12 17:43:42 apptest.log.2018-05-12
... ...
19. ps 命令 process status(进程状态)。
用于查看当前系统运行的进程状态信息。该命令选项非常多,这里仅介绍常用的组合选项。
1) 使用-ef组合选项,可以查看当前系统所有的进程信息:
1
2
3
4
$ ps -ef
UID PID PPID C STIME TTY TIME CMD
500 2878 1 0 12:37 pts/0 00:00:24 /usr/local /jdk1.8.0_144/bin/java -Djava.util.logging.config.file=/home/fanlychie/applications/apache-tomcat-8.0.45/conf/logging.properties
... ...
如果想查看进程的PID或PPID可以选用该组合选项。其各字段的概述:
字段 描述 UID 进程所属的用户ID PID 进程ID PPID 进程的父ID C CPU使用比率 STIME 进程的启动时间 TTY 开始此进程的终端设备。“?” 表示是系统启动的。“tty1” 至“tty6” 表示是本机上登录者程序。“pts/0” 等,则表示为由网络连接进主机的程序。 TIME 进程使用的CPU总时间 CMD 启动进程的命令和参数
2) 使用aux组合选项(注意前面没有-),可以查看当前系统所有的进程信息:
1
2
3
4
$ ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
500 2878 0.1 18.3 2161124 89300 pts/0 Sl 12:37 0:27 /usr/local /jdk1.8.0_144/bin/java -Dcom.sun.akuma.Daemon=daemonized -Djava.awt.headless=true -DJENKINS_HOME=/var/lib/jenkins
... ...
如果想查看进程占用系统的内存和CPU信息可以选用该组合选项。其各字段的概述:
字段 描述 USER 进程的拥有者 PID 进程ID %CPU 进程占用的CPU百分比 %MEM 进程占用的内存的百分比 VSZ 进程使用的虚拟内存大小,单位:KB RSS 进程占用的固定内存大小,单位:KB TTY 开始此进程的终端设备。“?” 表示是系统启动的。“tty1” 至“tty6” 表示是本机上登录者程序。“pts/0” 等,则表示为由网络连接进主机的程序。 STAT 进程的状态。常见的状态有: START 进程的启动时间 TIME 进程使用的CPU总时间 COMMAND 启动进程的命令和参数
3) 使用-eo选项,可以自定义显示的进程信息字段:
1
2
3
4
5
$ ps -eo pid,pcpu,pmem,cmd
PID %CPU %MEM CMD
1 0.3 0.0 -bash
2 0.1 3.1 /usr/local /jdk1.7.0_72/bin/java
... ...
字段 描述 pid 进程的ID pcpu 进程的CPU百分占比%CPU pmem 进程的内存百分占比%MEM cmd 进程启动的命令CMD
4) 使用--sort选项,可以对指定的字段进行排序显示:
1
2
3
4
$ ps aux --sort -pmem
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 24742 0.1 3.1 2327664 123064 ? Sl 3月26 105:28 /usr/local /jdk1.7.0_72/bin/java
root 648 0.0 0.7 331532 27592 ? Ssl 3月25 0:47 /usr/bin/python
-pmem表示对进程的内存百分占比%MEM降序排序。-是降序,+升序(默认是升序)。
5) 找出最占内存的10个进程:
1
$ ps aux --sort -pmem | head
20. kill 命令 用于杀死一个进程。
该命令可以将给定的信号发送给指定的进程,如果没有给定明确的信号,则默认是发送15信号,该信号会终止进程。常用的信号有:
信号
描述
2
中断信号(ctrl + c)
9
强制终止
15
终止信号
19
暂停信号(ctrl + z)
1) 强制杀掉进程ID为“2878”的进程(可以结合ps命令来查看进程ID):
kill 9与kill -9的区别:kill 9:发送一个信号给进程并告诉进程,你需要终止运行。进程收到信号之后,并不会立刻停止运行,而是先释放占用的资源或者做一些其它的事情,并不会立即响应该信号,此进程仍然可能继续运行。kill -9:发送一个信号给进程并告诉进程,你需要立刻终止运行。该信号不能被捕获和忽略,进程收到后会立刻停止并退出。
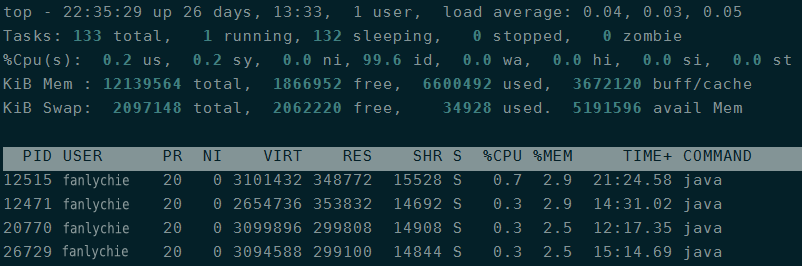
21. top 命令 用于查看进程占用系统资源的实时动态列表信息。
该命令输出的内容信息比较丰富,默认是每隔3秒自动刷新一次列表信息:
第一行(系统整体的统计信息):
22:35:29系统当前时间;up 26 days, 13:33系统连续运行的时间;1 user当前登录系统的用户数;load average: 0.04, 0.03, 0.05系统分别在1、5、15分钟内的平均负载;
第二行(进程的统计信息):
133 total进程的总数;1 running正在运行的进程数;132 sleeping休眠的进程数;0 stopped停止的进程数;0 zombie僵尸进程数;
第三行(CPU的统计信息):
0.2 us用户占用的CPU百分比;0.2 sy内核占用的CPU百分比;99.6 id空闲的CPU百分比;其余不一一列举了…
第四行(内存的统计信息):
12139564 total物理内存的总大小;1866952 free空闲可用的物理内存总大小;6600492 used已经使用的物理内存总大小;3672120 buff/cache缓冲内存的总大小;
第五行(交换分区的统计信息):
2097148 total交换分区的总大小;2062220 free空闲可用的交换分区的大小;34928 used已经使用的交换分区的大小;
有时候,我们可能会看到CPU的使用率占比超过100%。这其实是因为top命令是按照单个CPU核数来计算的。也就是说,如果一台服务器的CPU核数为4核,那么该服务器的CPU使用率占比理论上最高可达到400%。
当系统物理内存剩余量不是很富余的时候,那就应该引起注意了。Linux系统有一个OOM-killer(Out Of Memory killer)机制。当Linux内核检测到系统内存不足的时候,就会触发OOM-killer来挑选一个最耗内存的进程并杀掉这个进程以求释放一些内存出来。
除此之外,top命令第一行的load average也很直观的反应出当前系统的性能指标,当数值是在0.00~1.00之间,则表示系统当前的状况良好。超过1.00则表示系统已经超出负荷。而实际上,我们也可能会看到服务器平均负载超过1.00的情况。这也跟服务器的CPU核数有关。如果一台服务器的CPU核数为4核,那么,该服务器的平均负载能力理论上可达到4.00。当系统平均负载达到总的70%左右时,就应该有所行动,在事情变得更糟糕之前,去分析其造成的原因。分析的焦点应放在后两项的数值,因为第一项是1分钟内的平均负载,时间太短,一瞬间的高并发导致该值大幅度上涨是很有可能的。
进程信息区,部分字段的描述概要:
字段
描述
PID
进程ID
USER
进程所属者
VIRT
进程使用的虚拟内存总大小(KB)
RES
进程使用的物理内存大小(KB)
SHR
进程使用的共享内存的大小(KB)
%CPU
上次更新到现在的CPU时间占用百分比
%MEM
进程使用的物理内存百分比
COMMAND
进程启动的命令名或命令行
top命令支持按键操作响应事件,常用的按键操作有:
按键
描述
P(shift + p)
按%CPU降序排序结果
M(shift + m)
按%MEM降序排序结果
N(shift + n)
按PID降序排序结果
1(数字键1)
查看每个核的CPU使用情况
s
刷新的时间间隔(默认是5秒)
q
退出命令
1) 使用-d命令,可以指定列表信息刷新的时间间隔(默认是5秒):
2) 使用-p命令,可以指定特定的进程ID,只查看该进程的信息:
22. grep 命令 用于搜索文本内容。它能帮助你从大量的数据中快速找到你想要的数据。
1) 查看“catalina.out”日志文件中,出现“ERROR”文本的行:
1
$ grep ERROR catalina.out
2) 使用-n, --line-number选项,会对搜索匹配的行标记出其行号:
1
$ grep -n ERROR catalina.out
3) 使用-e, --regexp选项,可以一次指定搜索多个文本:
1
$ grep -n -e WARN -e ERROR catalina.out
用于搜索“catalina.out”文件中,出现“WARN”或“ERROR”文本的行。
4) 使用--color选项,可以在结果行中高亮显示搜索的文本:
1
$ grep --color catalina.out
5) 使用-E, --extended-regexp选项(等效于egrep),可以使用正则表达式来搜索文本:
1
$ egrep '\b2018-05-17 11:[0-9]+' catalina.out
用于搜索以“2018-05-17 11:”开头的行(即用于查看2018-05-17日11时的日志信息)。
常用的正则表达式表格:
元字符 描述 ^ 匹配搜索字符串开始的位置。如“^abc”用于匹配以“abc”字符串开头的行。 $ 匹配搜索字符串结尾的位置。如“abc$”用于匹配以“abc”字符串结尾的行。 \b 锚定词首或词尾。如“\bhello”表示以“hello”开始的词。 . 匹配除换行符“\n”之外的任何单个字符。如“a.c”可以匹配“abc”或“a2c”等。 ? 匹配零次或一次前面的字符或子表达式,等效于“{0,1}”。如“ab?c”可以匹配“abc”和“ac”。 匹配零次或多次前面的字符或子表达式,等效于“{0,}”。如“abc”可以匹配“abc”和“ac”和“abbc”等。 + 匹配一次或多次前面的字符或子表达式,等效于“{1,}”。如“ab+c”可以匹配“abc”和“abbc”等。 [ ] 匹配中括号的开始和结尾。 {n} 匹配前面的字符或子表达式正好n次。如“ab{2}c”匹配“abbc”。 {n,} 匹配前面的字符或子表达式至少n次。如“ab{2,}c”匹配“abbc”和“abbbc”等。 {,m} 匹配前面的字符或子表达式至多n次。如“ab{,2}c”匹配“ac”和“abc”和“abbc”。 {n,m} 匹配前面的字符或子表达式至少n次,至多m次。如“ab{2,3}c”匹配“abbc”和“abbbc”。 \w 匹配字母和数字,相当于“[0-9A-Za-z]” \W 匹配非字母和数字,相当于“[^0-9A-Za-z]”
6) 使用-v, --invert-match选项,可以反转查找:
1
$ ps -ef | grep java | grep -v grep
查看“java”进程信息,并且将grep java行的信息排除掉。
7) 使用-R, -r, --recursive选项,可以从一个目录中的所有文件中搜索:
23. find 命令 用于查找系统的文件。它能帮助你快速的定位和找到你想要的文件。
语法:find [查找的目录] [选项] [参数]
1) 使用-name选项,可以按文件的名称进行查找:
在当前目录(“.”表示当前目录,find命令查找时,会对给定的目录以及该目录下所有的子目录都进行查找)下,查找“*.log”文件。
find命令支持通配(*),为避免*被bash进行扩展,因此需要加引号。
2) 使用-type选项,可以按文件类型进行查找:
常见的文件类型有:
3) 使用-mmin选项(last modified minutes),可以查找在指定时间被更改过的文件或目录:
1
$ find . -name '*.log' -mmin -3
-3表示查找3分钟前。
4) 使用-exec command {} \;选项,可以执行一个任意的command命令:
1
$ find . -name '*.log' -exec cat {} \; > logs.txt
该命令是用于将当前目录下的所有的log文件的内容拼接成一个数据流重定向到logs.txt文件中。
其中的{}是与-exec选项搭配使用的一个特殊符,它最终会被替换为find命令匹配到的每个文件的文件名称。
24. su 命令 用于切换用户身份。用户身份变更时,需要输入变更的用户账户密码。特殊的,root用户切换到其它用户账户时,不需要密码。ctrl + d发送一个 exit 信号,用于快捷退出当前登录的用户账户,以返回切换前的用户身份。
su [user]可以切换当前的用户身份。默认su是切换为root用户:
它等效于:
切换为“testusr”用户:
切换用户身份后,不会改变用户所在的当前目录。
su - [user]切换当前的用户身份,并将工作目录改变为目标用户的“home”目录:
例如切换用户前是在“/home/fanlychie/myconfig”目录下,切换用户后是在“/home/testusr”目录下。
25. 前台和后台任务 后台进程也叫守护进程,是运行在系统后台的一种特殊的进程,它脱离了终端控制台的控制。
如果想要将一个进程放到后台去运行,只需在命令的末尾加&:
1
$ java -jar spring-boot-application.jar &
一般情况下,当用户退出终端时,用户启动的后台进程也会跟着退出。为了使进程可靠的在后台不间断的运行,可以使用nohup command &。
1
$ nohup java -jar spring-boot-application.jar &
默认情况下,nohup命令会将标准输出和标准错误输出重定向到当前目录下的“nohub.out”文件中。nohup并不能让进程在后台运行,但能让进程忽略挂断信号。用户退出终端或网络断开的情况下,nohup进程不会退出。
当我们使用nohup command &命令启动一个后台进程时,我们可能并不希望日志信息输出到前台或“nohub.out”文件中,特别是在使用脚本启动一个后台进程时。
1
$ nohup java -jar spring-boot-application.jar >/dev/null 2>&1 &
>/dev/null中的:>表示重定向到某个地方。默认是标准输出,即>等效于1>。/dev/null是系统的空设备文件,经常被用来当做垃圾箱使用。也有人把它比作“黑洞”,因为所有输出到这里的东西都会消失的无影无踪,在终端上也不会显示任何信息。
2>&1中的:>&是等同于的意思。2>&1则是表示将标准错误重定向到与标准输出相同的地方。
总的来说,这条命令的言外之意就是在后台启动一个服务,服务启动输出的信息和错误信息都不要显示在终端。
上面涉及到的“1”和“2”是文件描述符,文件描述符是用来描述输入和输出的整数。最常见的文件描述符:
文档类型
说明
文件描述符
stdin
标准输入
0
stdout
标准输出
1
stderr
标准错误
2
后台的任务(或称进程,或称作业)可以使用jobs命令来查看:
1
2
3
$ jobs
[1]- Running nohup java -jar spring-boot-application.jar > /dev/null 2>&1 &
[2]+ Stopped tail -f nohup.out
其中,[num]里面的数字表示的是任务序号,+号表示默认选择的任务。-号的任务需要通过任务序号来选择。
使用fg [num]命令可以将一个后台进程切换到前台,若fg命令后面没有指定任务序号,表示切换至默认的任务,即带+号的任务:
其等效于:
通过使用组合键ctrl + z也可以将一个前台进程暂停并且放到后台中。比如通过vi编辑文件或通过tail查看文件的时候,ctrl + z将其放入后台后,可以非常方便的切换回来。
命令bg [num]可以让一个后台暂停的进程变为继续运行。同样的,若bg命令后面没有指定任务序号,表示默认选择带+号的任务:
其等效于:
后台进程可以先切换至前台然后按ctrl + c强制中断杀死进程。也可以通过kill %num来杀死。
26. 磁盘空间 系统的磁盘空间是一种有限的存储介质资源。当系统磁盘空间使用快要爆满时,我们需要删除或移走部分文件以腾出更多可用的磁盘空间。掌握如何去查看服务器的磁盘空间的使用情况这就显得很重要了。df和du是 Linux 系统中用于查看系统磁盘使用情况的两个重要命令。
df(disk free,磁盘可用空间),用于查看服务器磁盘空间的使用情况:
1
2
3
4
5
$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda2 19G 3.1G 15G 18% /
tmpfs 238M 0 238M 0% /dev/shm
/dev/sda1 291M 34M 242M 13% /boot
参数-h, –human-readable是使用易读格式(人类更易懂的), 将数值自动转换为常见 M、G 等单位显示。
其中,Size 是磁盘总的容量,Used 是已用的空间,Avail 是剩余可用的空间(重要),Use% 是已用的空间的百分比。
du(disk usage,磁盘使用),用于查看文件或目录占用的磁盘空间大小:
1
2
3
$ du -h logs
81M logs/app
149M logs
参数-h, –human-readable是使用易读格式(人类更易懂的), 将数值自动转换为常见 M、G 等单位显示。
可以看出,logs目录总共占149M的磁盘空间。其中,logs/app目录共占81M,剩余的68M被logs根目录下的文件占用。如果想要查看各个文件占用的磁盘空间,可以追加使用-a, –all参数:
1
2
3
4
5
6
7
8
$ du -ha logs
332K logs/demo1.log
20K logs/demo2.log
68M logs/demo3.log
49M logs/app/app-demo2.log
33M logs/app/app-demo1.log
81M logs/app
149M logs
参数-s,--summarize仅显示总计,如统计当前路径下所有的文件或目录占用的磁盘空间:
1
2
3
$ du -sh *
1.2G apps
149M logs
如果只是想统计当前路径占用的磁盘空间可以使用du -sh(等效于:du -sh .):
27. 内存空间 free命令可用于查看系统内存的使用情况。
1
2
3
4
$ free -h
total used free shared buff/cache available
Mem: 11G 6.7G 155M 75M 4.7G 4.4G
Swap: 2.0G 20M 2.0G
参数-h, –human-readable是使用易读格式(人类更易懂的), 将数值自动转换为常见 M、G 等单位显示。
参数
描述
total
总的内存。
used
已使用的内存。
free
可用的内存。
shared
多个进程共享的内存。
buff/cache
缓冲区和缓存使用的内存。
available
可用的内存。当系统内存不足(没有足够的free内存可用时),就会从buff/cache中回收部分空间,以满足应用程序的需求。这是一个理想的值,它往往存在一些误差。
第一行Mem表示物理内存。第二行Swap是交换空间,它是磁盘上的一块区域。当系统的物理内存吃紧时,Linux 就会将内存中不常用的数据存储到 swap 分区上,这样就能腾出一些内存空间来为其他应用程序服务。当系统需要用到 swap 分区上存储的数据时,Linux 再将这些数据调入内存中。这就是换入和换出。swap 分区可以在一定程度上缓解内存不足的情况,但是它需要读写磁盘数据,所以性能不是很高。
28. wc 命令 word count(单词统计)。
用于统计文件或从标准设备读入的数据的行数、单词数和字符数。
参数-c, --bytes用于统计字符数:
1
2
$ wc -c zookeeper.out
60669 zookeeper.out
参数-w, --words用于统计单词数:
1
2
$ wc -w zookeeper.out
4169 zookeeper.out
参数-l, --lines用于统计行数:
1
2
$ wc -l zookeeper.out
491 zookeeper.out
29. netstat 命令 用于查看系统的网络状态信息。
使用-ant组合选项,可以查看所有的TCP连接状态信息:
-a, –all显示所有的socket链接-n, –numeric使用数字类型的IP地址显示-t, –tcp只显示TCP传输协议的链接
1
2
3
4
5
6
7
$ netstat -ant
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp6 0 0 :::20818 :::* LISTEN
tcp6 0 0 :::20809 :::* LISTEN
tcp6 0 0 10.10.10.171:20818 10.10.10.170:55648 ESTABLISHED
tcp6 0 0 10.10.10.171:20818 10.10.10.170:34580 ESTABLISHED
tcp6 0 0 10.10.10.171:20809 10.10.10.176:26379 ESTABLISHED
字段 描述 Local Address 本地地址和端口信息 Foreign Address 远程地址和端口信息 State 状态信息。常见的状态有:
使用-lntp组合选项,可以查看系统监听端口的所有进程信息:
-l, –listening只显示监听中的socket链接-n, –numeric使用数字类型的IP地址显示-t, –tcp只显示TCP传输协议的链接-p, –program显示正在使用此socket的进程PID和进程名称
1
2
3
4
5
$ netstat -lntp
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp6 0 0 :::20811 :::* LISTEN 20369/java
tcp6 0 0 :::20813 :::* LISTEN 20465/java
tcp6 0 0 :::20815 :::* LISTEN 20489/java
查找某个端口被哪个进程占用:
1
2
$ netstat -lntp | grep 8080
tcp6 0 0 :::8080 :::* LISTEN 7596/java
由此可见,8080端口被进程PID为7596的程序占用。然后可以通过ps命令查找出该进程所属的程序:
1
2
$ ps -ef | grep 7596
joinpay 7596 1 0 7月09 ? 00:04:26 /usr/local /jdk1.7.0_72/...
统计某个端口的服务当前的链接数量。如统计“20818”端口:
1
2
$ netstat -ant | grep ":20818" | wc -l
21
30. vi 命令 vi是 Linux 系统中的一个强大的编辑器。可用于文本的写入、替换、删除、查找等。vi编辑器的三种模式:
在命令模式下可以通过按键进行:
按键
说明
j
光标向下移动( ↓ )
k
光标向上移动( ↑ )
h
光标向左移动(←)
l
光标向右移动(→)
gg
文首
G
文尾
nG
n是一个数字,定位到第n行
0
行首(数字0)
^
行首
$
行尾
dd
删除光标所在的行
yy
复制光标所在的行
x
从光标高亮处(包括高亮处)开始向后(右)删除字符
X
从光标高亮处(不包括高亮处)开始向前(左)删除字符
p
将复制的内容粘贴在光标所在行的下一行
P
将复制的内容粘贴在光标所在行的上一行
u
还原动作
.
重复动作
?word
向上查找word字符串
/word
向下查找word字符串
n
同方向搜索(如果是“?”则是向上搜索,如果是“/”则是向下搜索)
N
反方向搜索(如果是“?”则是向下搜索,如果是“/”则是向上搜索)
在命令模式下,通过以下的操作可以进入插入模式:
按键
说明
i
在光标高亮处之前插入
I
在光标所在行的行首插入
a
在光标高亮处之后追加
A
在光标所在行的行尾插入
o
在光标所在行的下一行插入一个空行
O
在光标所在行的上一行插入一个空行
Esc
退出插入模式,回到命令模式
在命令模式下,通过以下的操作可以进入底行模式:
按键
说明
:w
保存
:q
退出
:w!
强制写入保存
:q!
强制退出
:wq
保存退出
:wq!
强制保存退出
:set nu
显示行号
:set nonu
不显示行号
:nohl
退出匹配的高亮显示
:s/表达式/替换字符/
替换当前行匹配到的第一个处
:s/表达式/替换字符/g
替换当前行匹配到的所有处
:%s/表达式/替换字符/g
替换文档中匹配到的所有处
ZZ
保存退出
ZQ
不保存退出
编辑“hello.txt”文件:
其文件内容如下:
输入:%s/o/O/g可将全部的“o”替换成“O”。
vi命令除了可以用来编辑文件之外,使用它来查看日志文件也是一个利器:
-R是只读模式,为避免不小心编辑到日志文件,最好加上此参数项。在vi编辑器里,你可以利用它强大的命令快捷的查看日志文件的内容。
N. rpm 命令 RedHat Package Manager(RedHat Linux操作系统的软件包管理工具)。
用于对“*.rpm”软件包进行安装、查询、卸载等。
N. vi 命令 01. 命令执行控制 使用;,||,&&分隔符,可以在一个命令行中执行多条命令。
[ ; ]
1
$ command1 ; command2 [ ; command3 ...]
command1执行不管成功与否,command2总是会继续执行。它相当于:
示例:进入目录,罗列指定字符开头的文件。
1
$ cd logs/ ; ll spring-boot-demo*
[ || ]
1
$ command1 || command2 [ || command3 ...]
command1执行失败时,command2才执行。command1执行成功时,command2不执行。即或逻辑。
示例:关闭防火墙,如果操作失败,输出 fail。
1
$ service iptables stop || echo "fail"
[ && ]
1
$ command1 && command2 [ && command3 ...]
command1执行成功时,command2才执行。command1执行失败时,command2不执行。即与逻辑。
示例:启动 Tomcat 应用,启动命令执行成功后,打开控制台查看日志。
1
$ ./bin/startup.sh && tail -f logs/catalina.out
02. 后台进程 如果想要将一个进程放到后台去运行,只需在命令的末尾加&。
示例:启动服务,并让其在后台运行。
1
$ java -jar spring-boot-application.jar &
一般情况下,当用户退出终端时,用户启动的后台进程也会跟着退出。为了使进程可靠的在后台不间断的运行,可以使用nohup command &。
示例:启动服务,并让其在后台不间断的运行。
1
$ nohup java -jar spring-boot-application.jar &
默认情况下,nohup命令会将标准输出和标准错误输出重定向到当前目录下的nohub.out文件中。nohup并不能让进程在后台运行,但能让进程忽略挂断信号。用户退出终端或网络断开的情况下,nohup进程不会退出。
03. 文件描述符 文件描述符是用来描述输入和输出的整数。最常见的文件描述符:
文档类型
说明
文件描述符
stdin
标准输入
0
stdout
标准输出
1
stderr
标准错误
2
示例:启动服务,并让其在后台不挂断的运行。
1
$ nohup java -jar spring-boot-application.jar >/dev/null 2>&1 &
上面已经介绍了nohup command &。我们这里主要来分析>/dev/null 2>&1片段的含义和作用:
第一部分:>是重定向到某个地方。默认是标准输出,即>等效于1>。
第二部分:/dev/null是系统的空设备文件,经常被用来当做垃圾箱使用。也有人把它比作“黑洞” ,为所有输出到这里的东西都会消失的无影无踪,在终端上也不会显示任何信息。
第三部分:>&是等同于的意思。2>&1则是将标准错误重定向到与标准输出相同的地方。
综上所述,这条命令的中心思想是:在后台运行服务,启动输出的信息和错误信息都不要显示在终端。
04. 前后台任务互切 上面介绍了&将进程放到后台去运行,使用jobs命令可查看后台进程:
1
2
3
$ jobs
[1]- Running nohup java -jar spring-boot-application.jar > /dev/null 2>&1 &
[2]+ Stopped tail -f nohup.out
[]里面的数字表示的是任务序号,+号表示默认选择的任务。-号的任务需要通过任务序号来选择。
fg [任务序号]可以将一个后台进程切换到前台,若fg命令后面没有指定任务序号,表示切换至默认的任务,即带+号的任务:
组合键ctrl + z也可以将一个前台进程放到后台并且暂停。比如通过vi编辑文件或通过tail查看文件的时候,ctrl + z将其放入后台后,可以非常方便的切换回来。
bg [任务序号]可以让一个后台暂停的进程变为继续运行。同样的,若bg命令后面没有指定任务序号,表示默认选择带+号的任务:
后台进程可以先切换至前台然后按ctrl + c强制中断杀死进程。也可以通过kill %任务序号来杀死。
05. 管道 管道“|” 可以将上一个命令的标准输出传递到下一个命令,并作为下一个命令的标准输入。
1
$ command1 | command2 [ | command3 ...]
查看目录下的文件,并显示行号:
1
2
3
4
5
$ ll | cat -n
1 total 40
2 drwxr-xr-x. 2 fanlychie fanlychie 4096 Nov 5 00:24 Desktop
3 drwxr-xr-x. 2 fanlychie fanlychie 4096 Nov 5 00:23 Documents
4 drwxr-xr-x. 2 fanlychie fanlychie 4096 Nov 5 00:23 Downloads
06. 空格 在 shell 编程中,空格是一个分隔符。一个常见的错误是:
1
2
3
#!/bin/bash
name = fanlychie
echo $name
执行的时候就会报:line 2: name: command not found。原因是=两边有空格,shell 会认为空格前面是一个命令,因此会报命令找不到的错误。
在 shell 编程中,空格的用法常见的有:
命令和选项之间必须有空格;
赋值符号=两边不能有空格;
测试语句[的两边要有空格,]的左边要有空格。如if [ condition ];
分隔符;、||、&&两边的空格可有可无;
管道|两边的空格可有可无;
07. 引号 当操作一个字符串时,如果该字符串中含有空格,那么,空格前面的字符就会被当成命令来执行。被引号包裹起来的字符串,shell 会将它当成一个普通的字符串对待,而不会去解析成命令来执行。
单引号
单引号''包裹的内容是所见即所得。
1
2
3
#!/bin/bash
sayhi='hello world'
echo $sayhi
执行结果:hello world
单引号里面引用的变量无效(所见即所得,任何变量都不会被替换)。
1
2
3
#!/bin/bash
sayhi='hello world'
echo 'You have one new message: $sayhi'
执行结果:You have one new message: $sayhi
双引号
双引号""包裹的内容,可以引用外部定义的变量。
1
2
3
#!/bin/bash
sayhi="hello world"
echo "You have one new message: $sayhi "
执行结果:You have one new message: hello world
反引号
反引号``(键盘左上角Esc正下方的键)包裹的内容,可以用于存储命令的输出,即命令替换。
1
$ echo "curr time: `date`"
执行结果:curr time: Sat Nov 11 14:17:15 UTC 2017
10. 文本搜索 文本搜索能力很重要。它能帮助你从大量的数据中快速定位和找到你想要的数据。常用的是通过grep命令完成。语法:grep [OPTIONS] PATTERN [FILE...]
示例:查找日志文件中,所有出现“ERROR” 字符串的地方:
示例:查找日志文件中,所有出现“ERROR” 字符串的地方,并打印行号:
参数:-n, --line-number
释义:搜索的结果显示文本在文件中的行号
1
$ grep -n ERROR access.log
示例:查找日志文件中,所有出现“ERROR”字符串的地方,并打印行号高亮显示:
参数:--color
释义:匹配的文本会被不同颜色高亮显示
1
$ grep -n --color ERROR access.log
示例:查找目录下所有的日志文件中,所有出现“ERROR” 字符串的地方,并打印行号高亮显示:
1
$ grep -n --color ERROR *.log
示例:查找日志文件中,所有出现“ERROR” 或“WARN” 字符串的地方,并打印行号高亮显示:
参数:-e, --regexp
释义:允许指定多个不同的搜索字符串
1
$ grep -n --color -e ERROR -e WARN access.log
示例:查找日志文件中,所有出现“Exception” 字符串的地方,并打印行号高亮显示:
参数:-E, --extended-regexp
释义:允许搜索串中使用正则表达式
1
$ grep -En --color '\b\w+Exception\b' access.log
egrep等效于grep -E。可以在搜索串中使用正则表达式来匹配。
1
$ egrep -n --color '\b\w+Exception\b' access.log
示例:查找日志文件中,最近出现“Exception” 字符串的10个地方,并打印行号:
1
$ egrep -n '\b\w+Exception\b' access.log | tail
附正则表达式表:
元字符
描述
^
匹配搜索字符串开始的位置。如“^abc”用于匹配以“abc”字符串开头的行。
$
匹配搜索字符串结尾的位置。如“abc$”用于匹配以“abc”字符串结尾的行。
.
匹配除换行符“\n”之外的任何单个字符。如“a.c”可以匹配“abc”或“a2c”等。
?
匹配零次或一次前面的字符或子表达式,等效于“{0,1}”。如“ab?c”可以匹配“abc”和“ac”。
*
匹配零次或多次前面的字符或子表达式,等效于“{0,}”。如“ab*c”可以匹配“abc”和“ac”和“abbc”等。
+
匹配一次或多次前面的字符或子表达式,等效于“{1,}”。如“ab+c”可以匹配“abc”和“abbc”等。
[]
匹配中括号的开始和结尾。
{n}
匹配前面的字符或子表达式正好n次。如“ab{2}c”匹配“abbc”。
{n,}
匹配前面的字符或子表达式至少n次。如“ab{2,}c”匹配“abbc”和“abbbc”等。
{,m}
匹配前面的字符或子表达式至多n次。如“ab{,2}c”匹配“ac”和“abc”和“abbc”。
{n,m}
匹配前面的字符或子表达式至少n次,至多m次。如“ab{2,3}c”匹配“abbc”和“abbbc”。
\w
匹配字母和数字,相当于“[0-9A-Za-z]”
\W
匹配非字母和数字,相当于“[^0-9A-Za-z]”
示例:从标准输入中搜索出现“java” 字符的地方:
1
2
3
$ ps -ef | grep java
root 1807 1 0 Nov11 ? 00:01:38 /usr/local /jdk1.8.0_144/bin/java -Dcom.sun.akuma.Daemon=daemonized -Djava.awt.headless=true -DJENKINS_HOME=/var/lib/jenkins -jar /usr/lib/jenkins/jenkins.war --logfile=/var/log /jenkins/jenkins.log --webroot=/var/cache/jenkins/war --daemon --httpPort=8080 --debug=5 --handlerCountMax=100 --handlerCountMaxIdle=20
500 4621 4164 0 00:23 pts/2 00:00:00 grep java
ps是用来查看进程信息,后续会讲到。看回上面输出的最后一行,通常情况下,它不是我们想要的,我们可以使用-v(--invert-match,反转匹配。即除了匹配外的其他所有行)参数将它过滤掉:
1
2
$ ps -ef | grep java | grep -v grep
root 1807 1 0 Nov11 ? 00:01:38 /usr/local /jdk1.8.0_144/bin/java -Dcom.sun.akuma.Daemon=daemonized -Djava.awt.headless=true -DJENKINS_HOME=/var/lib/jenkins -jar /usr/lib/jenkins/jenkins.war --logfile=/var/log /jenkins/jenkins.log --webroot=/var/cache/jenkins/war --daemon --httpPort=8080 --debug=5 --handlerCountMax=100 --handlerCountMaxIdle=20
示例:递归搜索目录下的所有文件中出现“Exception” 的地方,并打印行号高亮显示:
参数:-R, -r, --recursive
释义:从给定的目录开始递归所有的子目录
1
$ egrep -rn --color '\b\w+Exception\b'
11. 文件搜索 文件搜索的能力也很重要。它能帮助你快速的找到你想要的文件。常用的是通过find命令完成的。
示例:查找目录下的某个文件:
参数:-name
释义:根据文件的名称搜索
1
2
$ find . -name 'logging.properties'
./conf/logging.properties
示例:使用通配符查找目录下的所有的.properties文件:
1
$ find . -name '*.properties'
示例:查看目录下的所有的子目录:
参数:-type
释义:根据文件的类型搜索,常用的d(directory,目录)、f(regular file,文件)
示例:查看目录下的所有的文件:
示例:查找3分钟之内有流量进来的日志文件:
参数:-mmin(最后一次修改文件的时间)
释义:最近一次文件内容被修改的时间
1
$ find . -name '*.log' -mmin -3
示例:高级用法,执行一个命令。
参数:-exec command {} \;
释义:执行一个任意的command命令。
备注:{}是一个与-exec搭配使用的特殊符,它会被替换为find命令匹配到的每个文件的文件名称。
1
$ find . -type f -name '*.log' -exec cat {} \; > demo.txt
达到的效果就是,将当前所有的log文件的内容拼接成一个数据流重定向到demo.txt文件中。
12. 进程信息 当前系统运行的所有进程信息都可以用ps命令来查看,搭配kill命令可以随时杀死某个进程。
示例:查看当前系统所有的进程信息,常用的组合参数是-ef或aux(注意参数前面没有-):
1
2
3
$ ps -ef
UID PID PPID C STIME TTY TIME CMD
500 2878 1 0 12:37 pts/0 00:00:24 /usr/local /jdk1.8.0_144/bin/java -Djava.util.logging.config.file=/home/fanlychie/applications/apache-tomcat-8.0.45/conf/logging.properties
字段
描述
UID
进程所属的用户ID
PID
进程ID
PPID
进程的父ID
C
CPU 使用比率
STIME
进程的启动时间
TTY
开始此进程的终端设备。“?” 表示是系统启动的与终端无关。“tty1” 至“tty6” 表示是本机上登录者程序。“pts/0” 等,则表示为由网络连接进主机的程序。
TIME
进程使用的 CPU 总时间
CMD
启动进程的命令和参数
1
2
3
$ ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
500 2878 0.1 18.3 2161124 89300 pts/0 Sl 12:37 0:27 /usr/local /jdk1.8.0_144/bin/java -Dcom.sun.akuma.Daemon=daemonized -Djava.awt.headless=true -DJENKINS_HOME=/var/lib/jenkins
字段
描述
USER
进程的拥有者
PID
进程ID
%CPU
进程占用的 CPU 百分比
%MEM
进程占用的内存的百分比
VSZ
进程使用的虚拟内存大小,单位:KB
RSS
进程占用的固定内存大小,单位:KB
TTY
开始此进程的终端设备。“?”表示是系统启动的与终端无关。“tty1” 至“tty6” 表示是本机上登入者程序。“pts/0” 等,则表示为由网络连接进主机的程序。
STAT
进程的状态。常见的状态有:
START
进程的启动时间
TIME
进程使用的 CPU 总时间
COMMAND
启动进程的命令和参数
小结:ps命令的参数项非常多,掌握常用的参数组合项即可。如果只是查看进程的PID或PPID信息可选用ps -ef;如果要查看进程的PID和占用系统的内存和CPU信息可选用ps aux。
示例:使用ps命令列出的进程信息会比较多,可以通过管道结合more或less命令翻页查看:
提示:less命令可以通过键盘的PageUp键(↑)和PageDown键(↓)上下翻页,按q键退出。
示例:自定义显示的进程信息的字段,参数组合-eo:
释义:pid,pcpu,pmem,cmd是别名,分别对应PID,%CPU,%MEM,CMD。
1
2
3
4
$ ps -eo pid,pcpu,pmem,cmd
PID %CPU %MEM CMD
1 0.0 0.1 /sbin/init
2 0.0 0.0 [kthreadd]
示例:查看所有的进程并按CPU降序排序:
参数:--sort
释义:排序字段
排序:-pcpu表示按%CPU降序,+pcpu表示按%CPU升序,由于+是默认的,因此可简写为pcpu
示例:自定义显示的进程信息的字段并按CPU降序排序:
1
$ ps -eo pid,pcpu,pmem,cmd --sort -pcpu
示例:找出最耗CPU的10个进程信息:
1
$ ps aux --sort -pcpu | head
示例:查看所有的进程并按内存降序排序:
疑惑:像%CPU一样用别名来排序无效,这里借助管道通过sort命令来排序
参数:此为sort的参数,-r降序(若没有此参数,sort默认采用升序的顺序来排序),-n按数值来排序,-k列的索引(第一列的索引值为1,以此类推)
示例:自定义显示的进程信息的字段并按内存降序排序:
1
$ ps -eo pid,pcpu,pmem,cmd | sort -nrk 3
示例:找出最耗内存的10个进程信息:
1
$ ps -eo pid,pcpu,pmem,cmd | sort -nrk 3 | head
12. 杀死进程 通常情况下,残忍的杀死一个进程我们经常会使用kill命令。
该命令的中心思想是用来强行杀死PID为2878的进程。kill是用来终止进程的信号。-9是一个信号编号,表示强行杀死。除此之外,常见的信号编号还有:
信号编号
描述
2
当按下组合键“Ctrl + c”时会发出该信号
9
强行杀死
15
终止进程默认发送的信号
20
当按下组合键“Ctrl + z”时会发出该信号
13. top 命令 top命令可以实时的监控系统中各个进程的资源占用情况,经常用于服务器性能监控和分析。
top列出的信息内容非常丰富(部分信息与ps相似,不再赘述),默认每隔3秒钟自动刷新一次:
top命令在运行中的时候,可以通过一些按键来控制显示的信息结果,常用的有:
信号编号
描述
Shift + p
按%CPU排序结果
Shift + m
按%MEM排序结果
Shift + n
按PID排序结果
1
数字1,查看每个核的CPU使用情况
首先来看前5行信息的内容:
第一行,系统的统计信息:
22:35:29 up 26 days, 13:33表示系统连续运行的时间;1 user表示当前登录系统的用户数;load average: 0.04, 0.03, 0.05表示系统分别在1、5、15分钟内的平均负载;
第二行,进程的统计信息:
133 total表示进程的总数;1 running表示正在运行的进程数;132 sleeping表示休眠的进程数;0 stopped表示停止的进程数;0 zombie表示僵尸进程数;
第三行,CPU的统计信息:
0.2 us表示用户占用的CPU百分比;0.2 sy表示内核占用的CPU百分比;99.6 id表示空闲的CPU百分比;其余不一一列举了…
第四行,内存的统计信息:
12139564 total表示物理内存的总大小;1866952 free表示空闲可用的物理内存总大小;6600492 used表示已经使用的物理内存总大小;3672120 buff/cache表示缓冲内存的总大小;
第五行,交换分区的统计信息:
2097148 total表示交换分区的总大小;2062220 free表示空闲可用的交换分区的大小;34928 used表示已经使用的交换分区的大小;
示例:单独跟踪某个进程的运行状态:
参数:-d
释义:每隔多少秒刷新一次
参数:-p
释义:进程的ID
有时候,我们经常会看到CPU的使用率占比超过100%。你莫要惊慌,这是因为top是按照单个CPU核数来计算的。如果一台服务器的CPU核数为4核,那么,该服务器的CPU使用率占比最高可达到400%。
内存是真内存!你看到剩余多少就是多少,没有更多了。如果系统剩余物理内存不是很足了,那就要引起注意了。Linux系统有一个OOM-killer(Out Of Memory killer)机制。当Linux内核检测到系统内存不足的时候,就会触发OOM-killer来挑选一个最耗内存的进程并杀掉这个进程以求释放一些内存出来。
除了内存和CPU,top还有一个地方很直观的反应出当前系统的性能指标,那就是第一行的load average系统平均负载。0.00~1.00之间的数值表示系统状况良好。超过1.00表示系统已经超出负荷快要不堪重负了。而实际上,我们也经常会看到服务器平均负载超过1.00的情况。这也跟服务器的CPU核数有关。如果一台服务器的CPU核数为4核,那么,该服务器的平均负载能力可达到4.00。事实上,当系统平均负载达到70%左右时,你就应该有所行动,在事情变得更糟糕之前,去分析其造成的原因。分析的焦点应放在后两项的数值,因为第一项是1分钟内的平均负载,时间太短,一瞬间的高并发导致该值大幅度上涨是很有可能的。作为一个程序猿,对top的心得言尽于此。
14. 硬盘使用情况 掌握如何去查看服务器的硬盘空间使用情况以及在硬盘空间捉襟见肘如何去查找大文件也很重要。特别是对于一些吃硬盘的应用,比如文件系统、索引检索应用等。
示例:查看服务器硬盘空间使用情况:
命令:df
释义:disk free,磁盘可用空间
参数:-h, --human-readable
释义:易读格式, 指的是数值后面的单位,如:M、G 等
1
2
3
4
5
$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda2 19G 3.1G 15G 18% /
tmpfs 238M 0 238M 0% /dev/shm
/dev/sda1 291M 34M 242M 13% /boot
一般只看第一行就行,其它涉及Linux文件系统方面的知识有兴趣可以自行谷歌百度,这里不作描述。Size是磁盘容量,Used是已用的空间,Avail是剩余可用的空间(重要),Use%是已用的空间的百分比。
示例:查看文件或目录占用的磁盘空间大小:
命令:du
释义:disk usage,磁盘使用
参数:-h, --human-readable
释义:易读格式, 指的是数值后面的单位,如:M、G 等
1
2
3
$ du -h logs
81M logs/app
149M logs
可以看出,logs目录总共占149M的磁盘空间。其中,logs/app目录共占81M,剩余的68M被logs根目录下的文件占用。如果想要查看各个文件占用的磁盘空间,可以追加使用-a, --all参数:
1
2
3
4
5
6
7
8
$ du -ha logs
332K logs/demo1.log
20K logs/demo2.log
68M logs/demo3.log
49M logs/app/app-demo2.log
33M logs/app/app-demo1.log
81M logs/app
149M logs
示例:找出目录下最大的10个文件:
1
2
3
4
5
6
$ find . -type f -exec du -b {} \; | sort -nrk 1 | head
70938260 ./demo3.log
50838254 ./app/app-demo2.log
33759270 ./app/app-demo1.log
336939 ./demo1.log
17510 ./demo2.log
由于是要按数值大小排序,故这里不能使用-h参数,-b, --bytes是统计字节数,这样排序才准确。
查看目录的磁盘大小
15. 网络链接 还在为系统链接不了网络而烦恼?还在为系统自动获取IP每次客户端链接终端都要修改IP地址而烦恼?
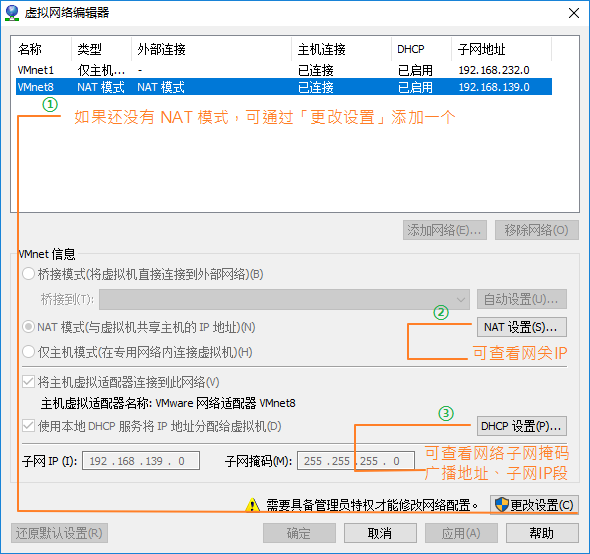
为你虚拟机的Linux操作系统设置静态IP!【工具:VMware;操作系统:CentOS6(CentOS7类似)】
在顶部菜单中选择编辑–>虚拟网络编辑器
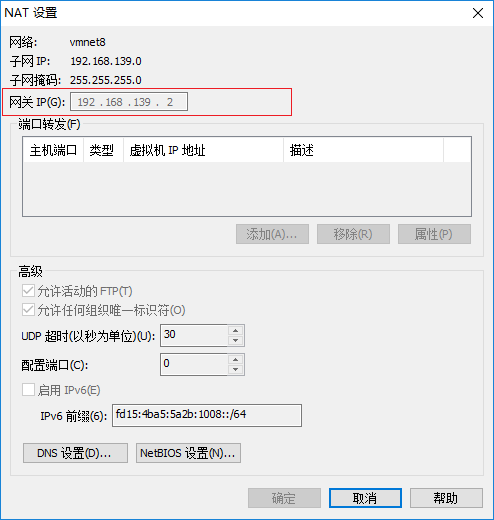
在 NAT 设置中查看网关IP:
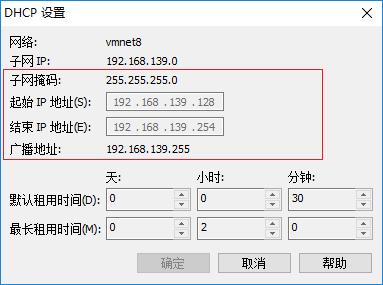
在 DHCP 设置中查看子网掩码、广播地址、子网IP段:
虚拟机Linux系统的网络适配器选择NAT模式。CentOS操作系统网卡的名称通常是以ifcfg-xxx的方式命名,你也可以使用ifconfig命令来查看系统的网卡名称。CentOS6的网卡名称通常是ifcfg-eth0。编辑网卡信息:
CentOS6 配置:1
2
3
4
5
6
7
8
9
DEVICE="eth0"
BOOTPROTO="static"
HWADDR="00:0C:29:66:3F:AB"
ONBOOT="yes"
UUID="96bcd1e9-5921-4cf9-bc0e-7c4b9d80e215"
IPADDR=192.168.139.129
NETMASK=255.255.255.0
GATEWAY=192.168.139.2
DNS1=192.168.139.2
CentOS7 配置:
1
2
3
4
5
6
7
... ...
BOOTPROTO="static"
IPADDR0=192.168.139.129
PREFIX0=24
GATEWAY0=192.168.139.2
DNS1=192.168.139.2
DNS2=8.8.8.8
网卡配置信息主要修改BOOTPROTO为static,以及添加后面几行的配置,DNS的值保持和网关一致。
重启网络服务:
验证网络是否可用(如果能ping通,说明网络可用):
16. 网络状态 如果想查看系统的网络状态信息,可以使用netstat命令。
参数:–numeric , -n
释义:使用数字类型的IP地址显示
参数:-a, –all
释义:显示所有经过TCP建立链接的Socket
参数:-t, –tcp
释义:只显示TCP传输协议的连线
1
2
3
4
5
6
7
$ netstat -ant
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp6 0 0 :::20818 :::* LISTEN
tcp6 0 0 :::20809 :::* LISTEN
tcp6 0 0 10.10.10.171:20818 10.10.10.170:55648 ESTABLISHED
tcp6 0 0 10.10.10.171:20818 10.10.10.170:34580 ESTABLISHED
tcp6 0 0 10.10.10.171:20809 10.10.10.176:26379 ESTABLISHED
这里主要来介绍后面的三列信息内容:
字段
描述
Local Address
本地地址和端口信息
Foreign Address
远程地址和端口信息
State
状态信息。常见的状态有:
示例:统计某个端口的服务当前的链接数量:
1
2
$ $ netstat -ant | grep ":20818" | wc -l
21
5. 数值运算 高高兴兴的写脚本:
1
2
3
4
5
#!/bin/bash
n1=1
n2=2
result=n1+n2
echo "n1 + n2 = $result "
执行结果:n1 + n2 = n1+n2(一脸懵逼有没有o(╯□╰)o)
在shell中,给变量赋予数字类型的值最终也是以字符串的方式存储的,如果想要让它们变得像数字一样能够进行数值运算,可以采用以下的方法。
5.1 let 使用let作数值运算时,变量名前不需要加$符号,适用于整数运算:
1
2
3
4
5
let result=n1+n2
let result++
let result--
let result+=1
let result-=1
5.2 $[ ] 使用$[ ]作数值运算时,变量名前不需要加$符号,[]里面可以有空格,适用于整数运算:
5.3 $(( )) 使用$(( ))作数值运算时,变量名前不需要加$符号,(())里面可以有空格,适用于整数运算:
5.4 expr 使用expr作数值运算时,变量名前需要加$符号,适用于整数运算:
5.5 bc 以上列举的方法都只适用于整数。如果要对小数进行运算,可以使用bc(数值运算的高级工具):
1
2
3
4
5
#!/bin/bash
n1=1.234
n2=2
result=`echo "$n1 * $n2 " | bc`
echo "n1 * n2 = $result "
除此之外,你还可以使用scale来指定需要保留的小数位数,中间用定界符分号来隔开:
1
result=`echo "scale=2; $n1 * $n2 / 1" | bc`
注:scale只对除法、取余、乘幂有效,对乘法无效,所以上例除以了一个1来达到效果。